微信公众号

手机端

搜索




文/VR陀螺 元桥
在今年苹果开发者大会(WWDC 2023)上,库克(Tim Cook)延续了乔布斯“one more thing”的表达发布了新一代空间计算产品——Apple Vision Pro。
这是一个值得让人纪念的历史性时刻,看到了又一个“one more thing”时刻来临,更重要的是人机界面技术在苹果发布新品之后会将迎来全新的发展,人类在虚拟/增强现实层面的脚步又前进了一步。
之所以说“又”是因为在苹果未发布新品之前,OpenAI推出了ChatGPT以及GPT大模型,让人类彻底感受到AI能力的不凡,相应地AI技术在AR/VR领域的应用也凸显了出来,甚至带来了新一轮产业格局的变化。
AI+便被视为虚拟/增强现实产业发展的关键因素,更是推动产业走深的底层技术,而苹果一直作为行业“游戏规则的制定者”在AI层面的布局亦甚为久远。虽然在今年WWDC 2023大会上,苹果只字未提人工智能,但从此次发布会上的产品以及新品Vision Pro中便能够窥探出一二。
苹果超十年的AI布局
6月2日,据外媒马克・古尔曼的推特表示苹果正在招募人工智能方面的人才,而据外媒消息显示,自5月以来苹果在招聘门户网站上发布了至少88个与人工智能相关的职位,涵盖视觉生成建模、主动智能和应用AI研究等领域。
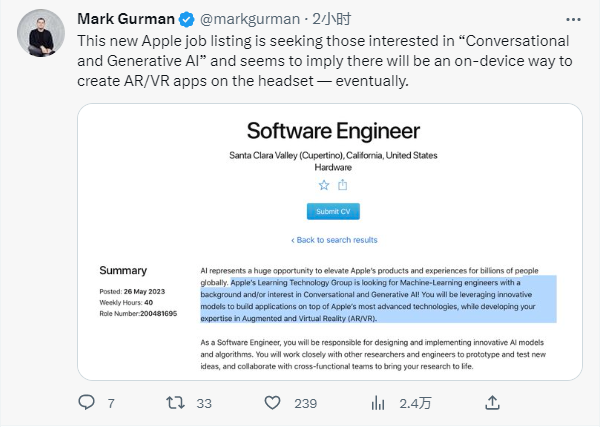
图:马克・古尔曼推特
所招聘的职位隶属于一个团队,该团队将“塑造生成式人工智能技术改变苹果移动计算平台的方式”,进一步表明iPhone以及Vision Pro等产品中的AI应用将会得到进一步扩展。
但苹果在人工智能层面的布局其实更早,2010年苹果以2亿美元的价格收购了Siri团队,并于2011年,随着iPhone 4s的发布,Siri以智能语音助手的身份亮相市场,如今被扩展到Mac、iPad甚至新发布的产品Vision Pro中。

图:Vision Pro中呼唤Siri(来源:网络)
据VR陀螺梳理,2010至今苹果收购的AI相关企业近30家,已知的收购金额超14亿美元(折合人民币近100亿)。大部分的收购与语音识别有关,应用方向集中在Siri上。但在生成式AI爆火的今年,Siri这一语音助手并未看到有太智能的进步,如当你问Siri一个问题时,Siri仍然还是会告诉你它搜索了哪些网站或者直接回答我不是很清楚。

图表:苹果收购一览(VR陀螺整理)
这种简单的操作相比如今会写稿、会编程的ChatGPT很容易让人忘记其实Siri也是人工智能,只是它与ChatGPT的工作原理不同。Siri的一大工作原理是当它接收到指令后,会优先传送到苹果的数据中心,数据中心会根据指令的内容进行分析,给出已知的答案;其次就是上传到云端,给出答案“我不太清楚,但我从网络上找到了这些信息”等等。而ChatGPT并没有本地的流程,直接利用庞大的计算与模型推算,无论是否理解指令,都会给出答案。

图源:网络
苹果向来对AI的发展都处于谨慎的态度,更喜欢强调机器学习功能以及为用户提供好处,正如此次WWDC 2023大会上,库克在接受媒体采访时所称“我们确实将它(AI)整合到我们的产品中,但人们不一定将其视为人工智能。”正因为如此,苹果才会限制Siri无节制发展。
不仅是Siri,在苹果产品中被忽略AI能力还有很多,像Apple Pencil的笔触追踪,FaceID的面容识别以及新品Vision Pro中的智能输入等,都呈现了AI的能力,下文会详谈。
另一方面,苹果的AI战略更注重两个点:性能与安全。在性能层面,苹果会将AI融入到产品中,提高产品的使用效果;而安全则是隐私,隐私是苹果历来注重的一个点,如2015年苹果收购Perceptio,这家公司主要从事人工智能照片分类,但除了图片自动分类外,Perceptio还可以保护隐私,无需将用户数据存储在云端。
2020年,苹果机器学习和人工智能战略的高级副总裁John Giannandrea以及产品营销副总裁Bob Borchers在一次访谈中便肯定了苹果的AI战略,并表示2018年苹果就加快了这一进程,让iPhone 中的 ISP 与神经引擎紧密合作(中央处理器),只是苹果不会向外说太多自己的AI能力,强调的则是Transformer 语言模型、机器学习等。

图:John Giannandrea(来源:网络)
而Giannandrea和Borchers也清楚地表明:如今,机器学习在苹果的产品功能中发挥了重要作用,机器学习在苹果的应用还会继续增强。
Apple Vision Pro中透露出的AI能力
在生成式AI爆火的今年,很多业内人士都预测称今年的WWDC 2023大会,苹果可能也会谈及AI,但在近2小时的发布会上,AI一次都未被提及,只是在其产品中无处不在。陀螺君针对Vision Pro所展现的AI能力进行了梳理,不难看出AR/VR若想进一步发展,必然也离不开AI技术的支持。
1.AI数字分身
AI的接入使数字人制作更加逼真,甚至在一些网站上,用户也可以根据自己的需求创建符合自己需求的数字人,而3D虚拟数字人也是VR头显进一步发展避不开的一节。Meta在去年就发布了Codec Avatar 2.0版本,比1.0进一步完成了逼真的数字人效果。

图源:网络
Vision Pro则是通过前置摄像头扫描人的面部信息,再基于机器学习技术,系统会使用先进的编码神经网络,为用户生成一个“数字分身”。并且当用户正通过FaceTime通话时,数字分身可以动态模仿用户的面部和手部的动作,保留数字分身的体积感和深度。

图源:网络
根据苹果表示,目前团队正在积极优化所述功能,在未来的visionOS更新中,数字人会变得更加逼真。另一方面,从发布会上的使用效果来看,数字分身的构建确实已经很逼真了,而且操作上也更加简单,仅需用设备扫一扫面部信息即可,可以说已经超越了目前市面上一些数字分身软件。
2.AI情绪检测
苹果在2016年就收购了一家AI情绪检测的公司,而今年据外媒消息显示,苹果正在研发一种名为Quartz的人工智能健康指导服务与跟踪情绪的新技术。
在此次Vision Pro发布后,苹果前研究员Sterling Crispin在推特中,透露了不少关于Vision Pro的黑科技。其中最令人惊叹的便是Vision Pro可以通过用户在沉浸式体验中的身体和脑部数据,来检测用户的心理状态。Sterling Crispin将其称为“脑机接口”或“读心术”。

图:Sterling Crispin的推特信息
而这项技术背后的主要原理则是,每个人在做每件事之前,瞳孔会做出反应,其中部分原因是你预计在你点击之后会发生一些事情。因此,苹果可以通过算法来监视你的眼睛行为。并实时重新设计UI,以创建更多这种预期的瞳孔反应,从而创建个人大脑的生物反馈。

图源:网络
3.更智能的输入方式
为了进一步满足用户对指引功能和空间内容的交互,Vision Pro引入了全新的输入系统,即由眼睛、手势和语音来进行交互,通过注视应用,“轻敲/轻拂”的手势进行应用的选择,或使用语音指令来浏览应用。

图源:网络
当眼睛注视到浏览器搜索框时,搜索框即进入听写输入状态,此时只需语音说出想要检索的内容,即可自动键入文本,进而进行搜索。使用 Siri 还能快速打开和关闭 app,播放媒体文件等。

图源:网络
虽然苹果并没有在Vision Pro介绍中强调输入法,但从iOS 17的介绍中可知,苹果更新的更加智能的输入法,不仅可以纠正拼写错误,甚至还可以纠正用户在输入过程中的语法错误。更为重要的是,基于设备端的机器学习,输入法还会根据用户每一次的键入自动改进模型,将输入法的自动纠正功能达到了前所未有的准确度。

图源:网络
4.新的操作系统“visionOS”
据苹果表示,建立在macOS、iOS和iPadOS的研发基础上,他们从零开始为Vision Pro设计了新的操作系统VisionOS,以实现对低延迟要求非常高的空间计算能力;分别内嵌了iOS框架、空间计算框架、空间音频引擎、3D空间引擎、注视点渲染引擎、实时驱动的子系统等。
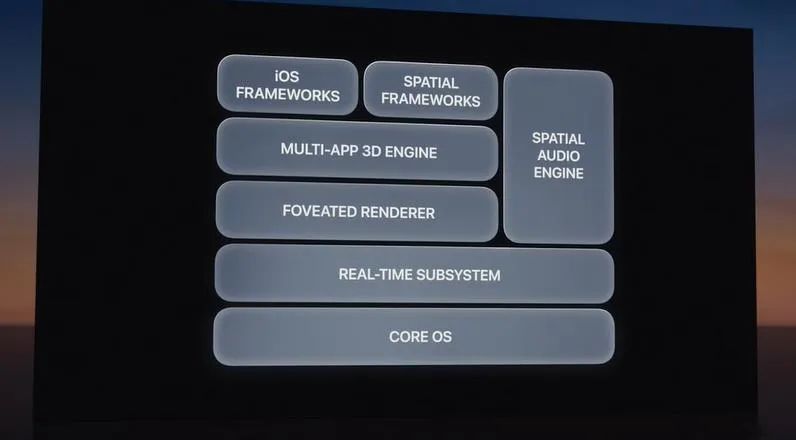
图源:网络
据苹果透露, visionOS将会有全新的 AppStore,未来会有更多专门针对 Vision Pro 开发的应用,例如 3D 解剖图等。
5.场景与动作识别
从以上可以看出Vision Pro的创新离不开AI的发展,在Vision Pro的空间音频计算、眼球动作以及手部行为的捕捉,这些都是人工智能技术所发力的领域,苹果凭借着M2和R1两颗芯片提供的算力支撑,顺利实现了人工智能的本地化部署。

图源:网络
而除了在Vision Pro隐藏了无处不在的AI能力外,苹果的所有产品几乎都能看到AI的技术,AI几乎已经渗透到了其产品的各个细节中,进一步表明了“AI+”在AR/VR层面发展的重要程度。
虽然苹果只字未提AI,但库克在一次访谈中表示“他个人正在使用 ChatGPT 并对这个独特应用程序感到兴奋,并表示苹果目前正密切关注该工具。”库克还补充说,“大型语言模型显示出巨大的希望,但也有可能出现诸如偏见、错误信息之类的事情,而且在某些情况下可能更糟。”
在笔者看来,AI作为一项技术本就该用于提升产品的性能,更好地为人类服务,过多的炒作或宣传反而失去了这项技术本该有的样子。同时,人工智能或者机器学习在未来会变得更加普遍,对于生成式AI,苹果或许并没有以大众希望的样子而展开,但相信苹果默默将其融于产品后一定可以提升用户的体验,让人眼前一亮。
“AI+”,AR/VR发展关键的一环
之前陀螺君曾在一篇文章中分析过“AI+”对产业竞争格局的影响,可点击阅读《搅局者GPT-4已来,AR产业竞争格局迈入新维度》,但抛开产业竞争格局来看,“AI+”也会为AR/VR设备的性能带来更大的提升。
今年,Meta发布了用于图像分割的新模型 Segment Anything Model (SAM),据Meta博客表示,SAM已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM足够通用,可以涵盖广泛的用例,并且可以在新的图像领域上即开即用,无需额外的训练。
如下图所示,SAM能很好的自动分割图像中的所有内容:

图源:网络
未来,SAM有望接入AR/VR设备, 如用于通过AR眼镜识别日常物品,用户仅需要使用目光注视物体,SAM便能够对用户看到的画面进行分割;配合AR眼镜应用,为用户展示所注视物体的提醒和说明。
另一方面,大语言模型的发展可以为AR/VR设备的语音交互与物体识别带来更具沉浸式的交互式体验。大语言模型能够理解更为复杂的自然语言,完成更复杂的自然语言处理任务,进而能够听懂用户以语音形式给出的复杂指令并做出响应,增强AR/VR设备语音交互方式的体验。随着大模型快速迭代,算力支持不断坚实,AR/VR的沉浸式体验的交互方式或更进一步丰富。
其次,生成式AI的发展,也会进一步降低AR/VR应用中3D创作的成本与门槛,解决AR/VR对3D素材大量的需求。关于生成式AI对3D创作的影响,陀螺君之前也写过一篇短文分析,可点击阅读《AI 3D创作来了?“抢饭碗”成真》。

图源:网络
最后,“AI+”融合AR/VR的发展已是产业发展的很大趋势,无论是从苹果的产品来看,还是Meta最新公布的布局亦或是AI对设备更新的影响,都表明了充分结合AI技术是未来AR/VR产业发展重要的一环。
但值得一提的是,AI的发展到现在还未看到明确的规范性文件出来,如果无限制发展AI给产业带来的负面影响也不可低估,如侵犯用户隐私、诈骗、数据泄露、认知偏见等等。
参考文章:
投稿/爆料:tougao@youxituoluo.com
稿件/商务合作: 林南(微信 19250561593) 六六(微信 13138755620)
加入行业交流群:林南(微信 19250561593)

元宇宙数字产业服务平台
下载「陀螺科技」APP,获取前沿深度元宇宙讯息